画像解析の勉強がてら、リア充の学習してみた
前書き
この記事は,SLP KBIT Advent Calendar 2021 の4日目の記事です。
今年もこの季節がやってきました。 クリスマス… 世の中は、リア充と非リアとサンタクロースの3種類に分類されます。 だったら、リア充と非リアを判別するWebアプリを製作しようと思い、 製作を始めました。 そのために、写真に写った人が男か女か判断する仕組みが必要です。 この記事では、男か女か分類してもらうAI君(画像解析のコード)を製作していきます。 今回、コードは全てPythonで書いてます。
目次
データ収集
画像解析を行うためには、画像データが必要です。 なので、初めに画像データを収集します。 今回は、googleで画像検索した結果を自動的に保存します。 検索ワードのフォルダも勝手に作成され、そのフォルダに保存されます。 便利ですね~。
from icrawler.builtin import BingImageCrawler #情報を入力 select_word = input("ほしい画像を教えてください:") select_num = input("何枚ほしいですか?:") #ダウンロード先のフォルダーを指定する crawler = BingImageCrawler(storage={"root_dir": "assets/" + select_word}) #google検索&ダウンロード #検索キーワードとダウンロード数を決定する crawler.crawl(keyword=select_word, max_num=int(select_num))
顔を切り取る
続いて、画像から顔だけを切り取っていきます。
顔を検知し、座標を取得します。
その座標部分だけを抜き取っていく操作を行っています。
顔の検知はopencvの中からhaarcascade_frontalface_default.xmlというとても便利なものを使わせていただきました。
ご先祖様の知恵に感謝!
import cv2 import glob import os from PIL import Image face_cascade_path = './haarcascade_frontalface_default.xml' face_cascade = cv2.CascadeClassifier(face_cascade_path) #バウンディングボックス座標データを取得 def Get_Bounding_Box(img_path): #画像を読み込む img_b = cv2.imread(img_path) if img_b is None: print("No Object") return -1 #ここでオブジェクトを検出 #バウンディングボックスもろもろ検出してる img_b_gray = cv2.cvtColor(img_b, cv2.COLOR_BGR2GRAY) #バウンディングボックスの座標情報をゲット face = face_cascade.detectMultiScale(img_b_gray) bbox = [] for x, y, w, h in face: bbox.append([x,y,x+w,y+h]) print(face) #バウンディングボックス座標データを返却 return bbox #物体だけを取り出す def Cut_draw(img_path, bbox_Coordinate, img_number, FM_name): #画像読み込み #RGBモードとしてやる RGBAモードだと上手く行かない img = Image.open(img_path).convert("RGB") #画像を切り取る #座標を格納する箱 item_position_list = [] #座標を一個ずつ読み取る for item_position in bbox_Coordinate: for item_coordinate in item_position: item_position_list.append(item_coordinate) #取得した座標のところだけを抜き取る img_crop = img.crop(item_position_list) img_crop.convert("RGB") #画像出力 img_crop.save("./images/" + FM_name + "/cut_image_drink{0}.jpg".format(img_number)) #座標リストを空にする item_position_list.clear() if __name__ == '__main__': FM_name = ["男性","女性"] for FM in FM_name: #使用する画像のパスを指定する img_path = "./assets/" + FM + "/*.jpg" #1つずつ画像パスを読み取る img_jpg = glob.glob(img_path) #画像番号 img_number = 1 #切り取った画像を保存するフォルダーを作成 os.makedirs("./images/" + FM, exist_ok=True) #画像を1つずつ処理する for img in img_jpg: #バウンディングボックスの座標データを取得&格納 bbox_Coordinate = Get_Bounding_Box(img) if type(bbox_Coordinate) is not int: #画像の抜き取り Cut_draw(img, bbox_Coordinate, img_number, FM) img_number += 1
余談になりますが、顔検知のはずなのに、半裸の男性の乳首がめっちゃ検知されます。
なんでや?乳首と人の顔は似てるのかな?
なので、手動で変な画像は取り除きました。
(大変だったな~(^-^))

サイズ変更
この後、画像データを学習させますが、サイズがバラバラだと不都合なことが多いです。 なので、64×64にサイズを変更させていきます。
import os import cv2 import glob FM_list = ["男性","女性"] for FM_name in FM_list: #フォルダーを作成している os.makedirs("./resize/" + FM_name, exist_ok=True) #読み取る画像のフォルダを指定 in_dir = "./images/" + FM_name + "/*.jpg" #出力先のフォルダを指定 out_dir = "./resize/" + FM_name #./assets_kora/drink/のフォルダの画像のディレクトリをすべて配列に格納している img_jpg = glob.glob(in_dir) #./assets_kora/drink/のファイルを一覧にする #画像の個数分繰り返し作業を行う for i in range(len(img_jpg)): img =cv2.imread(str(img_jpg[i])) #64×64サイズにしてる img_rot = cv2.resize(img,(64,64)) #パスを結合している fileName = os.path.join(out_dir, str(i) + "_" + str(i) + ".jpg") #画像を出力 cv2.imwrite(str(fileName),img_rot)
私は、このソースコードを実行した段階で、学習データとテストデータに分けました。 テストデータは、前から20枚程度選びました。
画像の水増し
私が調べたところ、画像データは1000枚くらいあったほうが望ましいらしいです。 変な画像を排除したり、テストデータに移したりすると、データが足りなくなります。 そこで、角度を変えたり、ぼかしたり、閾値を変化させてデータを作成していきます。 これで、私は100枚から850枚程度まで、データを増やすことに成功しました。
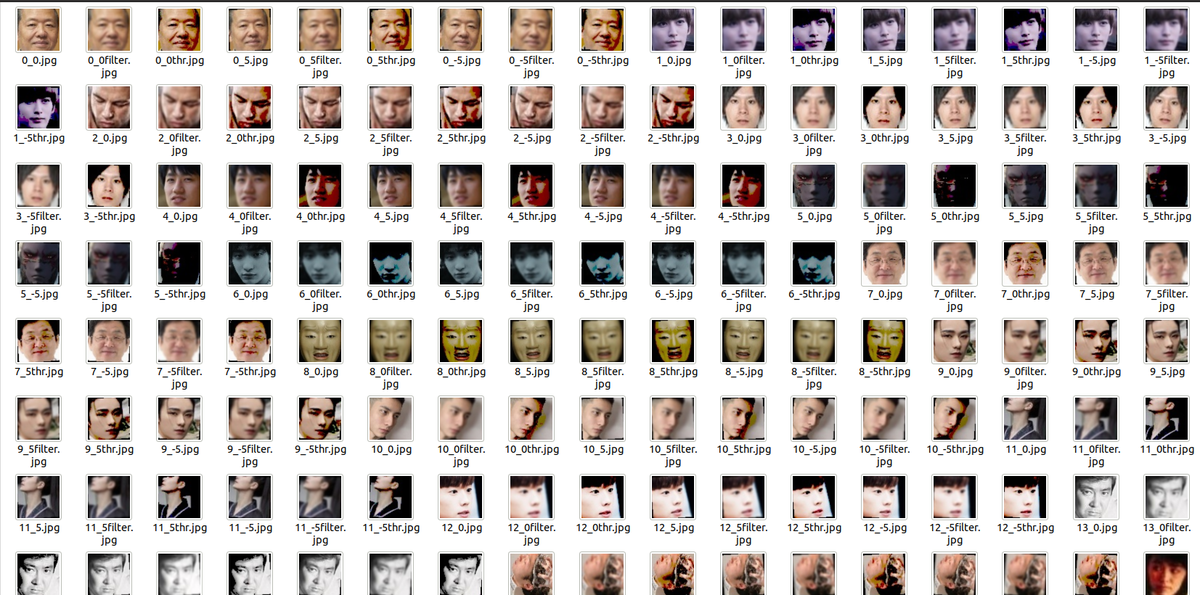
import os import cv2 import glob from scipy import ndimage FM_list = ["男性","女性"] for FM_name in FM_list: #フォルダーを作成している os.makedirs("./data/" + FM_name, exist_ok=True) #読み取る画像のフォルダを指定 in_dir = "./resize/" + FM_name + "/*.jpg" #出力先のフォルダを指定 out_dir = "./data/" + FM_name #./assets_kora/drink/のフォルダの画像のディレクトリをすべて配列に格納している img_jpg = glob.glob(in_dir) #./assets_kora/drink/のファイルを一覧にする #img_file_name_list =os.listdir("./) #画像の個数分繰り返し作業を行う for i in range(len(img_jpg)): img =cv2.imread(str(img_jpg[i])) #-------- #回転処理 #-------- for ang in [-5,0,5]: #ang配列を回転させて、画像の角度を変えているらしい img_rot = ndimage.rotate(img,ang) #64×64サイズにしてる img_rot = cv2.resize(img_rot,(64,64)) #パスを結合している fileName = os.path.join(out_dir, str(i) + "_" + str(ang) + ".jpg") #画像を出力 cv2.imwrite(str(fileName),img_rot) #-------- #閾値処理 #-------- #閾値を変更している #閾値を決め、値化の方法(今回はTHRESH_TOZERO)を決めている img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1] #パスを結合 fileName = os.path.join(out_dir, str(i) + "_" + str(ang) + "thr.jpg") #画像を出力 cv2.imwrite(str(fileName),img_thr) #---------- #ぼかし処理 #---------- #カーネルサイズ(5×5)とガウス関数を指定する #カーネルサイズはモザイクの粗さ的なもの #ガウス関数はよくわからない img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0) #パスを結合 fileName = os.path.join(out_dir, str(i) + "_" + str(ang) + "filter.jpg") #画像を出力 cv2.imwrite(str(fileName), img_filter)
学習
いよいよ学習です。
今回は、畳み込みニュートラルネットワークを使用し、学習しています。
下のように画僧を数値データで表し、2×2などのブロックに分けます。
そこから、最大値を抜き取り、画像の特徴を抽出していき、modelを作成します。

import os import cv2 import numpy as np #import matplotlib.pyplot as plt from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D from keras.models import Sequential from keras.utils.np_utils import to_categorical import tensorflow FM_name = ["男性","女性"] # 教師データのラベル付け X_train = [] Y_train = [] i = 0 #飲み物の名前ごとに処理する for name in FM_name: #ファルダーの中身の画像を一覧にする img_file_name_list=os.listdir("./data/"+name) #確認 print(len(img_file_name_list)) #画像ファイルごとに処理 for img_file_name in img_file_name_list: #パスを結合 n=os.path.join("./data/"+name+"/"+img_file_name) img = cv2.imread(n) #色成分を分割 b,g,r = cv2.split(img) #色成分を結合 img = cv2.merge([r,g,b]) X_train.append(img) Y_train.append(i) i += 1 # テストデータのラベル付け X_test = [] # 画像データ読み込み Y_test = [] # ラベル(名前) i = 0 for name in FM_name: img_file_name_list=os.listdir("./test/"+name) #確認 print(len(img_file_name_list)) #ファイルごとに処理 for img_file_name in img_file_name_list: n=os.path.join("./test/" + name + "/" + img_file_name) img = cv2.imread(n) #色成分を分割 b,g,r = cv2.split(img) #色成分を結合 img = cv2.merge([r,g,b]) X_test.append(img) # ラベルは整数値 Y_test.append(i) i += 1 #配列化 X_train=np.array(X_train) X_test=np.array(X_test) #ラベルをone-hotベクトルにする? y_train = to_categorical(Y_train) y_test = to_categorical(Y_test) # モデルの定義 model = Sequential() #畳み込みオートエンコーダーの動作 #ここの64は画像サイズ #画像サイズがあっていないと、エラーが発生する #3×3のフィルターに分ける model.add(Conv2D(input_shape=(64, 64, 3), filters=32,kernel_size=(3, 3), strides=(1, 1), padding="same")) #2×2の範囲で最大値を出力 model.add(MaxPooling2D(pool_size=(2, 2))) #畳み込みオートエンコーダーの動作 #3×3のフィルターに分ける model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same")) #2×2の範囲で最大値を出力 model.add(MaxPooling2D(pool_size=(2, 2))) #畳み込みオートエンコーダーの動作 #3×3のフィルターに分ける model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same")) #2×2の範囲で最大値を出力 model.add(MaxPooling2D(pool_size=(2, 2))) #1次元配列に変換 model.add(Flatten()) #出力の次元数を256にする model.add(Dense(256)) #非線形変形の処理をするらしい model.add(Activation("sigmoid")) #出力の次元数を128にする model.add(Dense(128)) #非線形変形の処理をするらしい model.add(Activation('sigmoid')) #出力の次元数を3にする #今回3種類のジュースなので、3 model.add(Dense(2)) #非線形変形の処理をするらしい model.add(Activation('softmax')) # コンパイル model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy']) # 学習<a name="学習"></a> history = model.fit(X_train, y_train, batch_size=512, epochs=90, verbose=1, validation_data=(X_test, y_test))#validation_data=(X_test, y_test) # 汎化制度の評価・表示 score = model.evaluate(X_test, y_test, batch_size=128, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #モデルを保存 model.save("./F_M.h5")
いろいろ書いてあり、分かりにくいですが、重要なのは
history = model.fit(X_train, y_train, batch_size=512, epochs=90, verbose=1, validation_data=(X_test, y_test))#validation_data=(X_test, y_test)の部分です。
batch_sizeとepochsのパラメータを変化させ、よいモデルを作成します。
batch_sizeは32か128か512のどれか、epochsは90~110の間を探れが大体うまくいきます。この場合の精度は以下の通りです。

76%と超微妙ですが、何枚か試した感じ問題はなかったので、OKとします。
検証用のソースコードは以下のものとなります。
import numpy as np import cv2 from keras.models import load_model from PIL import Image face_cascade_path = './haarcascade_frontalface_default.xml' face_cascade = cv2.CascadeClassifier(face_cascade_path) #バウンディングボックス座標データを取得 def Get_Bounding_Box(image): img_b = cv2.imread(image) if img_b is None: print("No Object") return -1 #ここでオブジェクトを検出 #バウンディングボックスもろもろ検出してる img_b_gray = cv2.cvtColor(img_b, cv2.COLOR_BGR2GRAY) #バウンディングボックスの座標情報をゲット face = face_cascade.detectMultiScale(img_b_gray) bbox = [] for x, y, w, h in face: bbox.append([x,y,x+w,y+h]) print(face) #バウンディングボックス座標データを返却 return bbox #画像を抜き取り、リサイズ def detect_object(image, img_url): bbox_Coordinate = Get_Bounding_Box(img_url) #配列の中が空かどうか判断 #空だったら、実行しない if len(bbox_Coordinate[0]) == 0: print("no object") else: #画像読み込み img = Image.open(img_url) #画像を切り取る #座標を格納する箱 item_position_list = [] #座標を一個ずつ読み取る for item_position in bbox_Coordinate: for item_coordinate in item_position: item_position_list.append(item_coordinate) #取得した座標のところだけを抜き取る img_crop = img.crop(item_position_list) #画像出力 img_crop.save("./stock_room/stock.jpg") #座標リストを空にする item_position_list.clear() #サイズ変更 image_resize = cv2.imread("./stock_room/stock.jpg") image_set = cv2.resize(image_resize, (64,64)) return np.expand_dims(image_set,axis=0) def detect_who(img): #予測 name="" print("predict:",model.predict(img)) nameNumLabel=np.argmax(model.predict(img)) print("argmax:",nameNumLabel) if nameNumLabel== 0: name="男性" elif nameNumLabel==1: name="女性" return name if __name__ == '__main__': model = load_model('./F_M.h5') # 判別したい画像 image_url = "./kakuninn/haruka.jpeg" image=cv2.imread(image_url) if image is None: print("Not open:") b,g,r = cv2.split(image) image = cv2.merge([r,g,b]) whoImage=detect_object(image,image_url) print(detect_who(whoImage)) #plt.imshow(whoImage) #plt.show()
次の記事は、今回作成したモデルを利用し、リア充非リア判別Webアプリを製作していきます。 上のソースコードは、https://github.com/IshigamiRyoichi/image_learn_appに置いてありますので、良ければ見に行ってください。 ps.この記事が12月4日に間に合ってますように