Canvas博物館
前書き
この記事は,SLP KBIT Advent Calendar 2022 の9日目の記事です。
これは、ひろゆきに「それって、あなたの感想ですよね」と言われた話です。 JavaScriptと言えば、Canvasだと思うのです。 Canvasを制する者は、JavaScriptを制し、オシャレになり、モテ男になるという言い伝えも存在します。
今回は、Cavas博物館というWebアプリケーションを作成し、みなさんと一緒にモテ男になろうと思います。
目次
全体の概要
- ディレクトリ構図
.
├── app.py
├── static
│ ├── css
│ │ └── style.css
│ └── js
│ ├── libs
│ │ └── perlin.js
│ └── museum.js
└── templates
└── museum.html
当Webアプリケーションは、始めのページに作品名が書かれたボタンを複数用意しています。好みの作品名のボタンをクリックすることでモーダル画面が登場し、Canvasで作成したアートを閲覧できる仕組みになっています。今回は、実際のアートの作成方法を省略し、アート表示までの流れを記載します。アートのコードが気になる方はこちらのgithubに公開してますので、ご確認を! また、今回作成するイメージはここに載せておきます。
モーダル画面
はじめにモーダル画面の処理を行う上でモーダル画面を開くボタンと閉じるボタン、もーだつ画面の情報を取得する必要があります。
const buttonOpen = document.getElementById(modalOpenId); const modal = document.getElementById(easyModal); const buttonClose = document.getElementsByClassName(modalCloseId)[0];
次に開くボタンを押すとモーダル画面が登場する処理を追加します。 モーふぁる画面は以下のCSSの設定が施されておます。
.modal{ display: none; position: fixed; z-index: 1; left: 0; top: 0; height: 100%; width: 100%; overflow: auto; background-color: rgba(0, 0, 0, 0.5); }
displayがnoneになっているため、表示されていません。
そのため、displayをblockに変更することで画面上に表示されます。
そこで、特定のボタンをクリックした際にcssのdisplayの設定が変更するように処理すれば、モーダル画面が登場します。
buttonOpen.addEventListener('click', modalOpen); function modalOpen() { modal.style.display = 'block'; }
一方、モーダル画面を閉じる際は、cssのdisplayの設定をnoneに変更することでモーダル画面を消すことができます。
buttonClose.addEventListener('click', modalClose); function modalClose() { modal.style.display = 'none'; }
Canvasの設定
続いて、Canvasの設定方法の説明です。設定と言っても、JavaScriptでCanvasに描画する準備方法を軽く記述したのみです。
私の場合は、以下のようなボタン配置にし、idを変更こうして複数のCanvasを作成しています。
<button id="rainbow-modalOpen" class="rainbow-button">rainbow</button> <div id="easyRainbowModal" class="modal"> <div class="modal-content"> <div class="rainbow-modal-header"> <h1>rainbow</h1> <span class="rainbow-modalClose">×</span> </div> <div class="modal-body"> <canvas id="rainbow" class="rainbow-canvas"></canvas> </div> </div> </div>
続いて、Canvasに描画するコンテキストを取得します。 まず初めにidを指定してCanvas要素を取得します。
const canvas = document.getElementById('rainbow');
続いて、コンテキストを取得します。今回は2次元でグラフィックを描画するため、引き数は2dを指定します。3次元でグラフィックを描画する場合は引数にwebglを指定します。
const context = canvas.getContext('2d');
FlaskでローカルWebサーバーを構築
最後にルート設定だけして、ローカルサーバーを立てて終わりにします。ルートは@app.route("ルート",メソッド設定)の書き方で設定可能です。ルート設定も含めたWebサーバーの構築は以下のコードで簡単に行えます。
from flask import Flask, render_template app = Flask(__name__) @app.route("/museum",methods=["GET"]) def museaum(): return render_template("museum.html") if __name__ == "__main__": app.run(debug=True)
終わりに
みなさん、モテ男になれましたか?
Webアプリ~リア充と非リア~
前書き
この記事は,SLP KBIT Advent Calendar 2021 の5日目の記事です。
前回の記事で男女を区別するmodelを作成しました。 今回は、作成したmodelとFlaskを使用し、リア充と非リアの判断を行うWebアプリを製作していきます。
目次
全体の概要
- ファイル構造
.
├── F_M.h5
├── demo_app.py
├── haarcascade_frontalface_default.xml
├── resize
├── stock
└── templates
├── main_page.html
└── uploads_page.html
demo_app.pyがバックエンドのメイン処理を行っています。F_M.h5が前回したmodel,haarcascade_frontalface_default.xmlは顔検知の際に使用するもの、resizeとstockは画像の処理を行う際に使用するディレクトリーです。
templatesは、フロントエンドのコードです。
バックエンド
処理の流れが以下のようになってます。
1. 画像から顔部分を抜き取る
1. 抜き取った画像サイズを変更する
1. 加工した画像から、写真に写ってる人が男性か女性か判断
1. 写真に写ってる人数や男女比からリア充か判断
今回は、LGBTも尊重しているため、ホモっプルかレズップルかも判断することにしました。これで、桜Trickのようなカップルを見つけれるかもしれません。
demo_app.py
from flask import Flask, request, render_template import os import cv2 import numpy as np from keras.models import load_model from PIL import Image import glob from werkzeug.utils import secure_filename # 画像をアップロードするフォルダー upload_folder = './uploads' # 画像の拡張子の制限 # set()で重複した要素を取り除く allowed_extenstions = set(["png","jpg","jpeg"]) # お決まり app = Flask(__name__) app.secret_key = "hogehoge" # 設定の保存 # upload_folderの設定を保存 UPLOAD_FOLDER = './uploads/' app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER # configの読み込み app.config.from_object(__name__) face_cascade_path = './haarcascade_frontalface_default.xml' face_cascade = cv2.CascadeClassifier(face_cascade_path) #バウンディングボックス座標データを取得 def Get_Bounding_Box(image): #画像を読み込む img_b = cv2.imread(image) if img_b is None: print("No No Object") return -1 #ここでオブジェクトを検出 #バウンディングボックスもろもろ検出してる img_b_gray = cv2.cvtColor(img_b, cv2.COLOR_BGR2GRAY) #バウンディングボックスの座標情報をゲット face = face_cascade.detectMultiScale(img_b_gray) bbox = [] for x, y, w, h in face: bbox.append([x,y,x+w,y+h]) #print(face) #バウンディングボックス座標データを返却 #print(bbox) return bbox #画像を抜き取り、リサイズ def detect_face(img, bbox_Coordinate): #一時保存先を指定 save_path = "./stock/stock.jpg" #リサイズしたものの出力先 out_dir = "./resize/stock_" i = 0 #配列の中が空かどうか判断 #空だったら、実行しない if len(bbox_Coordinate) == 0: #print("no object") return -1 else: #画像読み込み img_o = Image.open(img) #画像を切り取る #座標を一個ずつ読み取る for item_position in bbox_Coordinate: #取得した座標のところだけを抜き取る img_crop = img_o.crop(item_position) #画像出力 img_crop.save(save_path) #座標リストを空にする #item_position.clear() #サイズ変更 img =Image.open(save_path) #64×64サイズにしてる img_rot = img.resize((64,64)) img_rot.save(out_dir + str(i) + ".jpg") i += 1 return 0 def detect_who(img_url): model = load_model('./F_M.h5') img = cv2.imread(img_url) img_set = np.expand_dims(img,axis=0) #予測 name="" #print("predict:",model.predict(img_set)) nameNumLabel=np.argmax(model.predict(img_set)) if nameNumLabel== 0: name="男性" elif nameNumLabel==1: name="女性" print(name) return name # ボッチかやその顔が男性か女性など判断 def predict_Type(): fm_dic = {"男性":0, "女性":0} img_list = glob.glob("./resize/*.jpg") if len(img_list) == 1: return "ボッチですね!悲しい人" # 各顔写真がどっちか判断 for img in img_list: if detect_who(img) == "男性": fm_dic["男性"] += 1 elif detect_who(img) == "女性": fm_dic["女性"] += 1 #リア充か非リアかホモっプルか判断 if fm_dic["男性"] == 2 and fm_dic["女性"] == 0: return "ホモップル。やりますねー" if fm_dic["男性"] == 0 and fm_dic["女性"] == 2: return "レズップル!最高!!" if fm_dic["男性"] == 0 or fm_dic["女性"] == 0: return "リア充に見せかけた非リア" if fm_dic["男性"] == 1 and fm_dic["女性"] == 1: return "素晴らしいリア充" return "お前らは何や?" # resizeのファルダーを削除 def remove_image(): img_list = glob.glob("./resize/*.jpg") for img in img_list: os.remove(img) # リア充か非リアか判断 def riajuu_or_hiria(image_url): remove_image() image=cv2.imread(image_url) if image is None: return "Not open" # b,g,r = cv2.split(image) # image = cv2.merge([r,g,b]) bbox_Coordinate = Get_Bounding_Box(image_url) detect_face(image_url,bbox_Coordinate) return predict_Type() # 拡張子の確認 def allwed_file(filename): # .があるかどうかのチェックと、拡張子の確認 # OKなら1、だめなら0 return '.' in filename and filename.rsplit('.', 1)[1].lower() in allowed_extenstions # main画面 @app.route("/main_page",methods = ["GET", "POST"]) def main_page(): text = "アップロードテストです" return render_template("main_page.html",text = text) # アップロードしたファイルの処理 @app.route('/uploads_page',methods = ["GET", "POST"]) # ファイルを表示する def uploaded_file(): text = "アップしました" #データが届いたら if request.method == "POST": # ファイルを読み込む img_file = request.files['img_file'] # ファイル名を取得する filename = secure_filename(img_file.filename) # 画像のアップロード先URLを生成する img_url = os.path.join(app.config['UPLOAD_FOLDER'], filename) # 画像をアップロード先に保存する img_file.save(img_url) # 結果を表示 result = riajuu_or_hiria(img_url) return render_template('uploads_page.html', text=text, result=result) ## おまじない if __name__ == "__main__": app.run(debug=True)
フロントエンド
とりあえず、画像をアップロードするページと結果を表示するページの作成しました。
main_page.html
<!doctype html> <html lang="ja"> <head> <!-- 文字をutf-8に設定 --> <meta charset="utf-8"> <!-- どのデバイスで見ても見え方を一緒にする = レスポンシブデザイン --> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <title>アップロードテスト</title> <!-- cssの読み込み --> <!-- link rel="stylesheet" href="static/css/style.css" --> </head> <body class="text-center"> <h1>{{text}}</h1> <form action="/uploads_page" method=post enctype="multipart/form-data"> <p><input type=file id="img_file" name=img_file> <input type = submit value = Upload> </p> </form> </body> </html>

uploads_page.html
<!doctype html> <html lang="ja"> <head> <!-- 文字をutf-8に設定 --> <meta charset="utf-8"> <!-- どのデバイスで見ても見え方を一緒にする = レスポンシブデザイン --> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <title>アップロードテスト</title> <!-- cssの読み込み --> <!-- link rel="stylesheet" href="static/css/style.css" --> </head> <body class="text-center"> <h1>{{text}}</h1><br> {% if result %} <!--img src={{result_img}}--> <p>{{result}}</p> {% endif %} </body> </html>
私はサボっていますが、cssとかもっとしかっり書けば、GUIは豪華になります。
カップル検証
実際にうまくいってるか試してみます。
ネットで無作為にこの画像を選びました。
 結果がこちらです。
結果がこちらです。
 あれ...?
あれ...?
なぜか、男の娘カップルと判断されましたね('ω')
おそらく、画像解析部分がうまくいってません。頑張って、この部分を改良しようと思います。
画像解析の勉強がてら、リア充の学習してみた
前書き
この記事は,SLP KBIT Advent Calendar 2021 の4日目の記事です。
今年もこの季節がやってきました。 クリスマス… 世の中は、リア充と非リアとサンタクロースの3種類に分類されます。 だったら、リア充と非リアを判別するWebアプリを製作しようと思い、 製作を始めました。 そのために、写真に写った人が男か女か判断する仕組みが必要です。 この記事では、男か女か分類してもらうAI君(画像解析のコード)を製作していきます。 今回、コードは全てPythonで書いてます。
目次
データ収集
画像解析を行うためには、画像データが必要です。 なので、初めに画像データを収集します。 今回は、googleで画像検索した結果を自動的に保存します。 検索ワードのフォルダも勝手に作成され、そのフォルダに保存されます。 便利ですね~。
from icrawler.builtin import BingImageCrawler #情報を入力 select_word = input("ほしい画像を教えてください:") select_num = input("何枚ほしいですか?:") #ダウンロード先のフォルダーを指定する crawler = BingImageCrawler(storage={"root_dir": "assets/" + select_word}) #google検索&ダウンロード #検索キーワードとダウンロード数を決定する crawler.crawl(keyword=select_word, max_num=int(select_num))
顔を切り取る
続いて、画像から顔だけを切り取っていきます。
顔を検知し、座標を取得します。
その座標部分だけを抜き取っていく操作を行っています。
顔の検知はopencvの中からhaarcascade_frontalface_default.xmlというとても便利なものを使わせていただきました。
ご先祖様の知恵に感謝!
import cv2 import glob import os from PIL import Image face_cascade_path = './haarcascade_frontalface_default.xml' face_cascade = cv2.CascadeClassifier(face_cascade_path) #バウンディングボックス座標データを取得 def Get_Bounding_Box(img_path): #画像を読み込む img_b = cv2.imread(img_path) if img_b is None: print("No Object") return -1 #ここでオブジェクトを検出 #バウンディングボックスもろもろ検出してる img_b_gray = cv2.cvtColor(img_b, cv2.COLOR_BGR2GRAY) #バウンディングボックスの座標情報をゲット face = face_cascade.detectMultiScale(img_b_gray) bbox = [] for x, y, w, h in face: bbox.append([x,y,x+w,y+h]) print(face) #バウンディングボックス座標データを返却 return bbox #物体だけを取り出す def Cut_draw(img_path, bbox_Coordinate, img_number, FM_name): #画像読み込み #RGBモードとしてやる RGBAモードだと上手く行かない img = Image.open(img_path).convert("RGB") #画像を切り取る #座標を格納する箱 item_position_list = [] #座標を一個ずつ読み取る for item_position in bbox_Coordinate: for item_coordinate in item_position: item_position_list.append(item_coordinate) #取得した座標のところだけを抜き取る img_crop = img.crop(item_position_list) img_crop.convert("RGB") #画像出力 img_crop.save("./images/" + FM_name + "/cut_image_drink{0}.jpg".format(img_number)) #座標リストを空にする item_position_list.clear() if __name__ == '__main__': FM_name = ["男性","女性"] for FM in FM_name: #使用する画像のパスを指定する img_path = "./assets/" + FM + "/*.jpg" #1つずつ画像パスを読み取る img_jpg = glob.glob(img_path) #画像番号 img_number = 1 #切り取った画像を保存するフォルダーを作成 os.makedirs("./images/" + FM, exist_ok=True) #画像を1つずつ処理する for img in img_jpg: #バウンディングボックスの座標データを取得&格納 bbox_Coordinate = Get_Bounding_Box(img) if type(bbox_Coordinate) is not int: #画像の抜き取り Cut_draw(img, bbox_Coordinate, img_number, FM) img_number += 1
余談になりますが、顔検知のはずなのに、半裸の男性の乳首がめっちゃ検知されます。
なんでや?乳首と人の顔は似てるのかな?
なので、手動で変な画像は取り除きました。
(大変だったな~(^-^))

サイズ変更
この後、画像データを学習させますが、サイズがバラバラだと不都合なことが多いです。 なので、64×64にサイズを変更させていきます。
import os import cv2 import glob FM_list = ["男性","女性"] for FM_name in FM_list: #フォルダーを作成している os.makedirs("./resize/" + FM_name, exist_ok=True) #読み取る画像のフォルダを指定 in_dir = "./images/" + FM_name + "/*.jpg" #出力先のフォルダを指定 out_dir = "./resize/" + FM_name #./assets_kora/drink/のフォルダの画像のディレクトリをすべて配列に格納している img_jpg = glob.glob(in_dir) #./assets_kora/drink/のファイルを一覧にする #画像の個数分繰り返し作業を行う for i in range(len(img_jpg)): img =cv2.imread(str(img_jpg[i])) #64×64サイズにしてる img_rot = cv2.resize(img,(64,64)) #パスを結合している fileName = os.path.join(out_dir, str(i) + "_" + str(i) + ".jpg") #画像を出力 cv2.imwrite(str(fileName),img_rot)
私は、このソースコードを実行した段階で、学習データとテストデータに分けました。 テストデータは、前から20枚程度選びました。
画像の水増し
私が調べたところ、画像データは1000枚くらいあったほうが望ましいらしいです。 変な画像を排除したり、テストデータに移したりすると、データが足りなくなります。 そこで、角度を変えたり、ぼかしたり、閾値を変化させてデータを作成していきます。 これで、私は100枚から850枚程度まで、データを増やすことに成功しました。
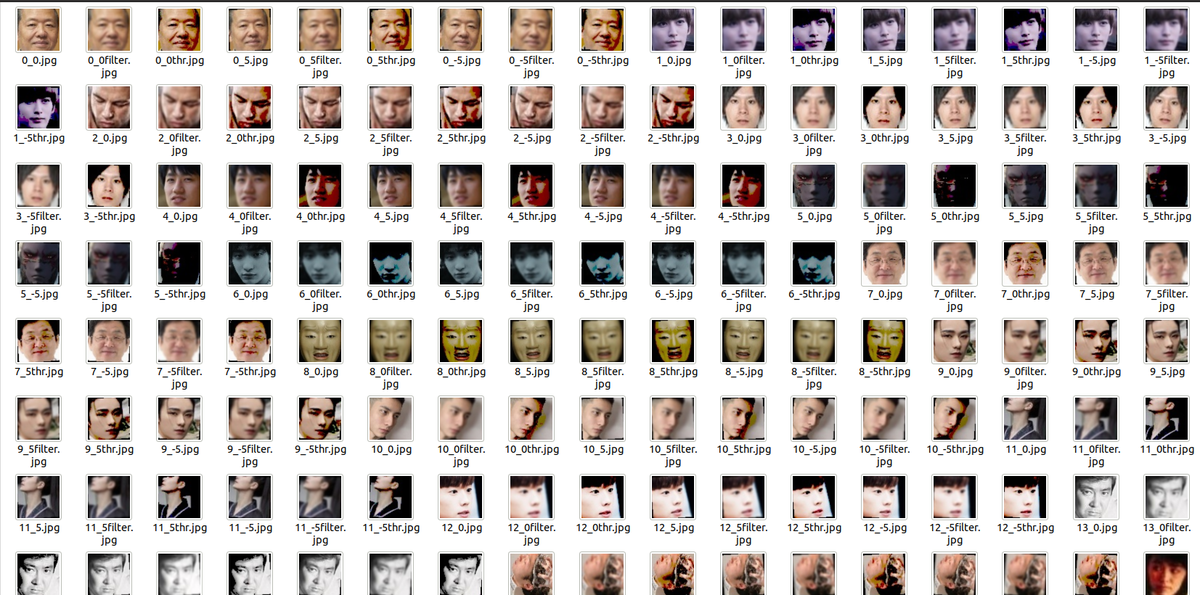
import os import cv2 import glob from scipy import ndimage FM_list = ["男性","女性"] for FM_name in FM_list: #フォルダーを作成している os.makedirs("./data/" + FM_name, exist_ok=True) #読み取る画像のフォルダを指定 in_dir = "./resize/" + FM_name + "/*.jpg" #出力先のフォルダを指定 out_dir = "./data/" + FM_name #./assets_kora/drink/のフォルダの画像のディレクトリをすべて配列に格納している img_jpg = glob.glob(in_dir) #./assets_kora/drink/のファイルを一覧にする #img_file_name_list =os.listdir("./) #画像の個数分繰り返し作業を行う for i in range(len(img_jpg)): img =cv2.imread(str(img_jpg[i])) #-------- #回転処理 #-------- for ang in [-5,0,5]: #ang配列を回転させて、画像の角度を変えているらしい img_rot = ndimage.rotate(img,ang) #64×64サイズにしてる img_rot = cv2.resize(img_rot,(64,64)) #パスを結合している fileName = os.path.join(out_dir, str(i) + "_" + str(ang) + ".jpg") #画像を出力 cv2.imwrite(str(fileName),img_rot) #-------- #閾値処理 #-------- #閾値を変更している #閾値を決め、値化の方法(今回はTHRESH_TOZERO)を決めている img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1] #パスを結合 fileName = os.path.join(out_dir, str(i) + "_" + str(ang) + "thr.jpg") #画像を出力 cv2.imwrite(str(fileName),img_thr) #---------- #ぼかし処理 #---------- #カーネルサイズ(5×5)とガウス関数を指定する #カーネルサイズはモザイクの粗さ的なもの #ガウス関数はよくわからない img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0) #パスを結合 fileName = os.path.join(out_dir, str(i) + "_" + str(ang) + "filter.jpg") #画像を出力 cv2.imwrite(str(fileName), img_filter)
学習
いよいよ学習です。
今回は、畳み込みニュートラルネットワークを使用し、学習しています。
下のように画僧を数値データで表し、2×2などのブロックに分けます。
そこから、最大値を抜き取り、画像の特徴を抽出していき、modelを作成します。

import os import cv2 import numpy as np #import matplotlib.pyplot as plt from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D from keras.models import Sequential from keras.utils.np_utils import to_categorical import tensorflow FM_name = ["男性","女性"] # 教師データのラベル付け X_train = [] Y_train = [] i = 0 #飲み物の名前ごとに処理する for name in FM_name: #ファルダーの中身の画像を一覧にする img_file_name_list=os.listdir("./data/"+name) #確認 print(len(img_file_name_list)) #画像ファイルごとに処理 for img_file_name in img_file_name_list: #パスを結合 n=os.path.join("./data/"+name+"/"+img_file_name) img = cv2.imread(n) #色成分を分割 b,g,r = cv2.split(img) #色成分を結合 img = cv2.merge([r,g,b]) X_train.append(img) Y_train.append(i) i += 1 # テストデータのラベル付け X_test = [] # 画像データ読み込み Y_test = [] # ラベル(名前) i = 0 for name in FM_name: img_file_name_list=os.listdir("./test/"+name) #確認 print(len(img_file_name_list)) #ファイルごとに処理 for img_file_name in img_file_name_list: n=os.path.join("./test/" + name + "/" + img_file_name) img = cv2.imread(n) #色成分を分割 b,g,r = cv2.split(img) #色成分を結合 img = cv2.merge([r,g,b]) X_test.append(img) # ラベルは整数値 Y_test.append(i) i += 1 #配列化 X_train=np.array(X_train) X_test=np.array(X_test) #ラベルをone-hotベクトルにする? y_train = to_categorical(Y_train) y_test = to_categorical(Y_test) # モデルの定義 model = Sequential() #畳み込みオートエンコーダーの動作 #ここの64は画像サイズ #画像サイズがあっていないと、エラーが発生する #3×3のフィルターに分ける model.add(Conv2D(input_shape=(64, 64, 3), filters=32,kernel_size=(3, 3), strides=(1, 1), padding="same")) #2×2の範囲で最大値を出力 model.add(MaxPooling2D(pool_size=(2, 2))) #畳み込みオートエンコーダーの動作 #3×3のフィルターに分ける model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same")) #2×2の範囲で最大値を出力 model.add(MaxPooling2D(pool_size=(2, 2))) #畳み込みオートエンコーダーの動作 #3×3のフィルターに分ける model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same")) #2×2の範囲で最大値を出力 model.add(MaxPooling2D(pool_size=(2, 2))) #1次元配列に変換 model.add(Flatten()) #出力の次元数を256にする model.add(Dense(256)) #非線形変形の処理をするらしい model.add(Activation("sigmoid")) #出力の次元数を128にする model.add(Dense(128)) #非線形変形の処理をするらしい model.add(Activation('sigmoid')) #出力の次元数を3にする #今回3種類のジュースなので、3 model.add(Dense(2)) #非線形変形の処理をするらしい model.add(Activation('softmax')) # コンパイル model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy']) # 学習<a name="学習"></a> history = model.fit(X_train, y_train, batch_size=512, epochs=90, verbose=1, validation_data=(X_test, y_test))#validation_data=(X_test, y_test) # 汎化制度の評価・表示 score = model.evaluate(X_test, y_test, batch_size=128, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #モデルを保存 model.save("./F_M.h5")
いろいろ書いてあり、分かりにくいですが、重要なのは
history = model.fit(X_train, y_train, batch_size=512, epochs=90, verbose=1, validation_data=(X_test, y_test))#validation_data=(X_test, y_test)の部分です。
batch_sizeとepochsのパラメータを変化させ、よいモデルを作成します。
batch_sizeは32か128か512のどれか、epochsは90~110の間を探れが大体うまくいきます。この場合の精度は以下の通りです。

76%と超微妙ですが、何枚か試した感じ問題はなかったので、OKとします。
検証用のソースコードは以下のものとなります。
import numpy as np import cv2 from keras.models import load_model from PIL import Image face_cascade_path = './haarcascade_frontalface_default.xml' face_cascade = cv2.CascadeClassifier(face_cascade_path) #バウンディングボックス座標データを取得 def Get_Bounding_Box(image): img_b = cv2.imread(image) if img_b is None: print("No Object") return -1 #ここでオブジェクトを検出 #バウンディングボックスもろもろ検出してる img_b_gray = cv2.cvtColor(img_b, cv2.COLOR_BGR2GRAY) #バウンディングボックスの座標情報をゲット face = face_cascade.detectMultiScale(img_b_gray) bbox = [] for x, y, w, h in face: bbox.append([x,y,x+w,y+h]) print(face) #バウンディングボックス座標データを返却 return bbox #画像を抜き取り、リサイズ def detect_object(image, img_url): bbox_Coordinate = Get_Bounding_Box(img_url) #配列の中が空かどうか判断 #空だったら、実行しない if len(bbox_Coordinate[0]) == 0: print("no object") else: #画像読み込み img = Image.open(img_url) #画像を切り取る #座標を格納する箱 item_position_list = [] #座標を一個ずつ読み取る for item_position in bbox_Coordinate: for item_coordinate in item_position: item_position_list.append(item_coordinate) #取得した座標のところだけを抜き取る img_crop = img.crop(item_position_list) #画像出力 img_crop.save("./stock_room/stock.jpg") #座標リストを空にする item_position_list.clear() #サイズ変更 image_resize = cv2.imread("./stock_room/stock.jpg") image_set = cv2.resize(image_resize, (64,64)) return np.expand_dims(image_set,axis=0) def detect_who(img): #予測 name="" print("predict:",model.predict(img)) nameNumLabel=np.argmax(model.predict(img)) print("argmax:",nameNumLabel) if nameNumLabel== 0: name="男性" elif nameNumLabel==1: name="女性" return name if __name__ == '__main__': model = load_model('./F_M.h5') # 判別したい画像 image_url = "./kakuninn/haruka.jpeg" image=cv2.imread(image_url) if image is None: print("Not open:") b,g,r = cv2.split(image) image = cv2.merge([r,g,b]) whoImage=detect_object(image,image_url) print(detect_who(whoImage)) #plt.imshow(whoImage) #plt.show()
次の記事は、今回作成したモデルを利用し、リア充非リア判別Webアプリを製作していきます。 上のソースコードは、https://github.com/IshigamiRyoichi/image_learn_appに置いてありますので、良ければ見に行ってください。 ps.この記事が12月4日に間に合ってますように
悪魔の数字サイトを作ってみたその2
前書き
この記事は,SLP KBIT Advent Calendar 2020 の6日目の記事です。 adventar.org 先にその1を閲覧することをお勧めします。
cd-donki-gorira.hatenablog.com
目次
本編
hello_controller.rb
このファイルは、受け取ったデータを処理するファイルとなっています。 ソースコードが以下のものとなります。
class HelloController < ApplicationController #protect_from_forgery #正しい誕生日を入力しているか判断 def eroor_birthday(mouth,day) if mouth.to_i == 2 && day.to_i > 29 then return -1 elsif mouth.to_i == 4 && day.to_i > 30 then return -1 elsif mouth.to_i == 6 && day.to_i > 30 then return -1 elsif mouth.to_i == 9 && day.to_i > 30 then return -1 elsif mouth.to_i == 11 && day.to_i > 30 return -1 end return 0 end #6の倍数以外の処理 def not_six(mouth,day) sum = mouth + day six_six_2 = (mouth*2 + day*2) six_six_3 = six_six_2 * 3 ans = six_six_3 / sum @str1 = 'だけど、初めに' + mouth.to_s + ' × 2' + ' + ' + day.to_s + ' × 2をし,' + six_six_2.to_s + 'になる' @str2 = '次に' + six_six_2.to_s + ' × 3を行い、' + six_six_3.to_s + 'になる' @str3 = '最後に' + sum.to_s + 'でわると' + ans.to_s + 'になる' @str4 = 'よって、悪魔の数字である!' end #悪魔の数字か判断 def jugde(mouth,day) if mouth.to_i == 6 && day.to_i == 6 then return mouth + '月も' + day + '日も、6です。悪魔じゃん。' elsif mouth.to_i % 6 ==0 && day.to_i % 6 == 0 then return mouth + '月も' + day + '日も、6の倍数なので悪魔の数字です。あなたは、めちゃくちゃ不幸です。' elsif mouth.to_i % 6 ==0 then return mouth + '月は、6の倍数なので悪魔の数字です。あなたは、不幸です。' elsif day.to_i % 6 == 0 then return day + '日は、6の倍数なので悪魔の数字です。あなたは、不幸です。' elsif mouth.to_i == 2 && day.to_i == 29 then return 'うるう年じゃなーか!悪魔じゃん!!' else not_six(mouth.to_i,day.to_i) end return '6の倍数じゃねーじゃん!面白くねーなぁ(´・ω・`)' end #メインで動かしているところ def index if request.post? then @title = '悪魔による結果です' @image = "fantasy_succubus.png" if params['s1'] && params['s2'] @msg = params['s1'] + '月' + params['s2'] + '日ですね' if eroor_birthday(params['s1'],params['s2']) == 0 then @result = jugde(params['s1'],params['s2']) else @result = '西暦のことも分かんねーのか?クズ' end else @msg = 'not selected...' end else @title = '悪魔の数字サイトへようこそ' @image = "character_akuma.png" @msg = 'select List...' end end end
今回、HelloController < ApplicationControllerで既存のクラスの機能を継承して新しいクラスを作成しています。
コントローラのクラスは、基本的にApplicationControllerを継承させると良いです。
def indexの中身についてですが、受け取った誕生日を元に条件分けを行っています。条件ごとに文字列やファイル名を@~に返却しています。
def not_sixでは、いちゃもんを考え文字列を複数返却し、それらを組み合わせて無理やり文章にしています。
 こんな感じでメッセージを返します。画像は、1パターンしか載せてませんが、メッセージは何パターンか用意してます。
こんな感じでメッセージを返します。画像は、1パターンしか載せてませんが、メッセージは何パターンか用意してます。
index.html.erb
このファイルは、アプリ内の画像やテキストやボタンの位置などのレイアウトを設定するファイルです。
ソースコードは、以下のようなものとなっています。
<h1 class="display-4"><%= @title %></h1>
<div>
<%# app/assets/images %>
<%= image_tag @image, alt: "Rails icon", id: "assets", class: "image", width: "300px" %>
</div>
<p1><%= '誕生日月を選んでください' %></p1>
<%= form_tag(controller: "hello", action: "index")do %>
<%= select_tag('s1',
options_for_select(["1","2","3","4","5","6","7","8","9","10","11","12"])) %>
<%= '月'%>
<%= select_tag('s2',
options_for_select(["1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29","30","31"])) %>
<%= '日'%>
<%= submit_tag("Click") %>
<% end %>
<p2><%= @msg%></p2><br><br>
<p2><%= @result%></p2><br>
<p3><%= @str1%></p3><br>
<p3><%= @str2%></p3><br>
<p3><%= @str3%></p3><br>
<p3><%= @str4%></p3><br>
初めにclassにdispaly-4と言う値を設定しています。これは、Bootstrapというフレームワークを使用しているためだそうです。
<%# app/assets/images %>は、画像を置いてるフォルダを指定しており、<%= image_tag @image, alt: "Rails icon", id: "assets", class: "image", width: "300px" %>で画像を表示しています。
selct_tagでは、誕生月と日の選択肢を設定しています。[]の中身を変更することで、選択肢を変更することができます。
<h>や<p>のようなタグは、見出しと文字列の塊を表しています。
hello.scss
このファイルは、装飾を行うためのファイルです。今回は、文字の色大きさを設定しています。
body {
color: rgb(23, 23, 23);
font-size:28px;
}
h1 {
color: rgb(15, 235, 147);
margin: 25px 0px;
}
p2 {
color: rgb(250, 16, 16);
}
p3 {
color: rgb(255, 161, 60);
}
color: rgbは、色を指定しています。RGBで指定を行っているので、赤と緑の青の割合で決定します。
font-sizeとmarginは、文字のサイズを設定しています。
application.html.erb
このファイルは、Webページ全体のレイアウトを記述するファイルであり、Railsアプリでデフォルトで使うものとなっていま。
ソースコードは、以下のようになっています。
<!DOCTYPE html>
<html>
<head>
<title>RailsApp</title>
<%= csrf_meta_tags %>
<%= csp_meta_tag %>
<%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %>
<%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %>
<link rel="stylesheet"
href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/
bootstrap.css">
</head>
<body class="container">
<%= yield %>
</body>
</html>
色々書いていますが、今回は<link rel="stylesheet"
href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/
bootstrap.css">と<body class="container">を追記するだけで大丈夫です。
前者の文を追記するだけで、CDNからBootatrapのスタイルシートを読み込むことができます。
後者の文は、Bottstrapを使うためのお約束だそうです。
routes.rb
このファイルは、ルーティング情報を割りてるファイルとなっています。 ソースコードは、以下の通りです。
Rails.application.routes.draw do # For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html get 'hello/index'#ルーティンの登録 https://localhost:3000/hello/indexを登録 helloはコントローラ名 indexはアクション名 get 'hello', to: 'hello#index'#HelloControllerクラスのindexメソッドを呼び出している get 'hello/other' post 'hello/index' post 'hello', to: 'hello#index' end
getでアドレスにルーティングを登録しています。
postは、アクセス許可をするために記述します。また、データを新規登録するアクションでも使用します。
おわり
作ってみて、こんだけのファイルを管理するのは大変だと感じましたが、一個一個は簡単だと感じました。 hello_controller.rbの中身を変更すると、自分好みのアプリを制作できると思います。少しでも参考になれば、幸いです。 個人的には、ログイン画面を追加したいと考えています。
参考文献
- 掌田津耶乃 Ruby on Rails6 超入門 秀和システム 2020年発行
- 【Rails入門】ルーティング 閲覧日2020-11-30 https://www.sejuku.net/blog/13078
- scssの基本的な書き方 閲覧日2020-11-30 https://qiita.com/nchhujimiyama/items/8a6aad5abead39d1352a
- Railsのimage_tagの使い方を現役エンジニアが解説【初心者向け】 閲覧日2020-11-30 https://techacademy.jp/magazine/22075
悪魔の数字サイトを作ってみたその1
前書き
この記事は,SLP KBIT Advent Calendar 2020 の1日目の記事です。 adventar.org
今回は、Ruby on Railsを使用して、悪魔の数字サイトというものを作ってみました。
サイトと言っても、アプリですが…
ざっくりと概要を話すと、すべての誕生日にいちゃもんを付けて、悪魔が悪魔の数字ですと返答するサイトです。
はっきり言って、糞ですね。
サイトの内容を無視すれば、役立つこともあると思いますので、良かったら参考にしてください。
最終的には、以下の画像のものが出来上がります。

目次
悪魔の数字
そもそも、悪魔の数字とはどういうものか知っていますか?
キリスト教の世界では、「666」という数字が悪魔的な意味を持ち、不吉な数字とされちます。
そのことから、6がつく数字と6の倍数の数は、悪魔の数と言われてます。
自分の誕生日を教えると、不吉ですと答えるサイトを作ったわけですが、
冷静に考えて馬鹿だなぁーと思います。
環境構築
開発環境
インストール
初めに、RubyとRailsをインストールします。Rubyは以下のサイトから、Railsは以下のコマンドを実行してください。
gem install rails
準備
続いて、アプリとコントローラを作成します。 作成するために以下のコマンドを実行してください。
rails new RailsApp(アプリケーション名)
cd RailsApp(アプリケーション名)
rails generate controller hello(コントローラ名)
新しいファイルとフォルダーがたくさん作成されましたが、
今回は主にhello_controller.rb,index.html.erb,hello.scss,application.html.erb,routes.rbの5つのファイルを使用します。
サーバーの実行方法
cd RailsAppコマンドでRilsAppフォルダまで移動し、rails serverもしくは、rails sコマンド打ち込むとサーバーが起動します。
ブラウザからlocalhost:3000にアクセスすることで、サーバーを確認することができます。
サーバーを終了する際は、CntrlキーとCキーを同時に押してください。以下のようなメッセージが出ますので、yを入力してください。
その2へ
1つの記事にまとめるつもりでしたが、文量が多くなったので2つの記事に分けます。ここまでは、Railsの環境構築を主にやってきましたが、その2では各ファイルの中身に触れていきます。後日、投稿しますので気になる方はご覧ください。
cd-donki-gorira.hatenablog.com
ここまでの参考文献
- 6月6日は悪魔の日 閲覧日2020-11-30 https://tcs-kazu.com/blog/president/20200606-993/
- Railsガイド 閲覧日2020-11-30 Ruby on Rails ガイド:体系的に Rails を学ぼう
- 掌田津耶乃 Ruby on Rails6 超入門 秀和システム 2020年発行
暗号ツール Webアプリケーション その2
前書き
この記事は,SLP KBIT Advent Calendar 2019 の20日目の記事です。
この記事は、「暗号ツール Webアプリケーション その2」です。その1を見ていない人は、先にその1を閲覧してもらえるとありがたいです。
目次
Webアプリケーション
続いて、Webアプリケーションの作り方について簡単に説明します。
まず、初めに文字を表示させてみましょう。 今回は、やっほーと表示させましょう。
文字を表示させるには、以下のようなプログラムになります。
require 'sinatra' require 'sinatra/reloader' enable :sessions class App < Sinatra::Base get '/' do 'やっほー' end end App.run!
require 'sinatra'は、sinatraというフレームワークの組み込むための宣言です。
require 'sinatra/reloader'は、ソースコードが変更された時、サーバに適応してくれる便利な機能と思っておいてください。 get '/' do~end は、'/'にgetメソッドでアクセスされたら、do~endの内容が実行されます。
Ruby {ファイル名}.rbで実行し、ブラウザからhttp://localhost:4567でアクセスします。
以下のように表示されると思います。

次に、erbファイルを利用して文字を表示させたいと思います。 プログラムは、以下のようなものになります。
rbファイル
class App < Sinatra::Base get '/' do @title = 'やっほー' @subtitle = 'ここは、富士参か?' erb :{erbのファイル名} end end App.run!
erbファイル
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title><%= @title %></title> </head> <body> <form action="/" method="post"> <h4><%= @title %></h4> <p><%= @subtitle %></p> </form> <br> </body> </html>
@titleと@subtitleに文字列を代入し、erbファイルで表示しています。
ブラウザには、以下のように表示されると思います。

次にテキストとボタンを付け加えていきましょう。 <input type=" " name=" " value=" ">のコードを付け加えます。typeのところをtextにすればテキスト、submitにすればボタンが生成されます。nameは変数、valueは属性を設定しています。今回は暗号ボタンと復号ボタンを付け加えましょう。また、暗号を生成するWebアプリケーションと分かりやすいようにtitleとsubtitleも’暗号ツール!’と’使ってね!’に変えたいと思います。
付け加えたプログラムが以下のものになります。
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title><%= @title %></title> </head> <body> <form action="/" method="post"> <h4><%= @title %></h4> <p><%= @subtitle %></p> <input type="text" name="sts1"> <input type="submit" value="暗号"> <br> <input type="text" name="sts2"> <input type="submit" value="復号"> <br> </form> <br> </body> </html>
以下のように表示されると思います。

作業もいよいよ終盤です。 ここから、一気に完成させようと思います。現段階では、同じフォームの中にボタンが2つあります。1つのフォームに1つのボタンしか設定できないため、フォームをもう1つ作成し、送信先を区別します。区別するため<form action="/" method="post">の"/"を"/cip"と"/dec"に変えます。続いて送信したデータを受け取る部分でrbファイルに作成します。その時、post "/cip" do ~ endとpost "/dec" do ~ endのコードを付け加えます。<form action="/" method="post">では、ユーザーがボタンを押したとき'/'に対してpostを送信し、それをサーバが受け取ります。'/'に対してpostが送られた時にdo~endの内容が実行されます。この部分でテキストの文字列を暗号化、復号を行います。なので、この中にその1で考えた暗号化と復号のプログラムを挿入します。その際、@before1と@before2にtextの文字列、@result1に暗号化した文字列、@result2に復号した文字列を代入し表示します。
プログラムは、以下のようになります。
rbファイル
require 'sinatra' require 'sinatra/reloader' enable :sessions class App < Sinatra::Base get '/' do @title = '暗号復号ツール!' @subtitle = '使ってね!' erb :{erbのファイル名} end post '/cip' do @title = '暗号復号ツール!' @subtitle = '使ってね!' @before1 = params[:sts1].to_s keyword = params[:sts1].to_s code = [] j = 1 keyword.chars.each do |char| if (65 <= char.ord && char.ord <= 90) then num1 = char.ord num2 = 77 - num1 num5 = 2 * num2 + 1 + num1 end if (97 <= char.ord && char.ord <= 122) then num1 = char.ord num2 = 109 - num1 num3 = 2 * num2 + 1 + num1 num4 = num3 - 96 if (num4 == 26) then num5 = 99 elsif (num4 % 3 == 0) then num4 = num4 - 1 num6 = (num4 + 3) % 26 num5 = num6 + 97 elsif (num4 % 3 == 1) then num5 = num4 + 97 else num5 = num4 + 98 end elsif(48 <= char.ord && char.ord <= 58)then num1 = char.ord - 48 num2 = (num1 + j) % 10 num5 = num2 + 48 if(j >= 3)then j = 1 else j = j + 1 end end code << num5.chr end @result1 = code.join("") erb :index end post '/dec' do @title = '暗号復号ツール!' @subtitle = '使ってね!' @before2 = params[:sts2].to_s keyword = params[:sts2].to_s code = [] j = 1 keyword.chars.each do |char| if (65 <= char.ord && char.ord <= 90) then num1 = char.ord num2 = 77 - num1 num5 = 2 * num2 + 1 + num1 end if (97 <= char.ord && char.ord<=122)then num = char.ord if(num == 97)then num3 =120 elsif((num+1)%3==0)then num1 = num - 97 num2 = (num1 - 1) % 26 num3 = num2 + 97 elsif((num+2)%3==0)then num1 = num - 97 num2 = (num1 - 2) % 26 num3 = num2 + 97 else num1 = num - 97 num2 = (num1 - 3) % 26 num3 = num2 + 97 end num4 = 109 - num3 num5 = 2 * num4 + 1 + num3 elsif(48 <= char.ord && char.ord <= 58) num1 = char.ord - 48 num2 = (num1 - j) % 10 num5 = num2 + 48 if(j >= 3)then j = 1 else j = j + 1 end end code << num5.chr end @result2 = code.join("") erb :index end end App.run!
erbファイル
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title><%= @title %></title> </head> <body> <form action="/cip" method="post"> <h4><%= @title %></h4> <p><%= @subtitle %></p> <input type="text" name="sts1"> <input type="submit" value="暗号"> <br> <span><%= @before1 %></span> <br> <span><%= @result1 %></span> </form> <br> <form action="/dec" method="post"> <input type="text" name="sts2"> <input type="submit" value="復号"> <br> <span><%= @before2 %></span> <br> <span><%= @result2 %></span> </form> </body> </html>
以下のように表示されます。

 このように暗号化前の文字列と暗号化後の文字列を表示させます。
このように暗号化前の文字列と暗号化後の文字列を表示させます。
終り
以上で紹介が全て終りました。やってみた感想として、意外と簡単にWebアプリケーションが作れるんだと思いました。まぁ、大きなWebアプリケーションを作成していないからかもしれませんが。世間では、Rubyはオワコンという声もありますが、使っていて非常に書きやすく楽しかったので、気に入りました。使用頻度は、下がっていく一方と予想されますが、私はもう少し使ってみようと思います。今後、もう少し大きなWebアプリケーションを作成できれば、いいなぁーと思います。
暗号ツール Webアプリケーション その1
前書き
この記事は,SLP KBIT Advent Calendar 2019 の20日目の記事です。
皆さんは、暗号にどれほど興味がありますか。普段、私が使っている連絡ツールにも暗号は使われています。
今回は、難しい暗号には挑戦しませんが、簡単な暗号方程式を考え、暗号を生成するWebアプリケーションを作成しました。
その方法を紹介したいと思います。
目次
開発環境
- Windows10
- ruby 2.6.5
インストール
gem install sinatra
暗号方程式
今回、3つの暗号方程式を紹介します。
1つ目は大文字のアルファベット、2つ目は小文字のアルファベット、3つ目は数字を暗号化する方程式です。
これから紹介する暗号方程式は、ASCIIコードという文字データを用いて考えました。また、10進数の値で考えているため、10進数のデータで説明します。
1つ目は、下の図のように「M」と「N」を境に鏡状に文字を反転させる方程式です。

例えば、Aという文字をASCIIコードで表すと65、Zは90になります。単純にAをZにしたいとき25を足せばよいです。しかし、MをNにしたいとき、25を足しても上手くいきません。そのため、25の数値を変化させる必要があります。
変化させるにあたって、25とはどんな数値か考えてみましょう。もちろん、AからZまでの差でもありますが、細かく分ければ、AからM MからN NからZの差を足したものだとも考えられます。MからNまでの差は1でNからZまでの差はAからMの差と同じです。AからMまでの差を2倍したものに1足した値が25です。つまり、文字を鏡状に反転させるには、特定の文字からMまでの差を2倍して1足した値をその文字に足せば、反転させることができます。
上に記述した方法では、NからZの文字をAからMに反転させることはできないと疑問に持つ人がいるかもしれません。試しにZで計算してみましょう。
ASCIIコードに直すと、Zは90でMは77です。
2*(77-90)+1=-25 90-25=65
上の式のように65という値になりました。ASCIIコードで65はAを表します。このように、NからZの値もAからMの値に
反転させることができます。
これをプログラムで表すと以下のようになります。
puts "パスワードを入力してください" keyword = gets.chomp puts "暗号化前: #{keyword}" code = [] keyword.chars.each do |char| if (65 <= char.ord && char.ord <= 90) then num1 = char.ord num2 = 77 - num1 num3 = 2 * num2 + 1 + num1 end code << num3.chr end puts "暗号化後: #{code.join("")}"
実行結果
パスワードを入力してください ABM 暗号化前: ABM 暗号化後: ZYN
2つ目は、下の図のように1文字目は1つずらし、2文字目は2つずらし、3文字目は3つずらし、再び4文字目は1つずらすような、1、2、3文字分ずらす操作を繰り返す方程式です。

| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b | d | f | e | g | i | h | j | l | k | m | o | n | p | r | q | s | u | t | v | x | w | y | a | z | b |
上の表を見てもらえば分かるように、変換後bが2回出てきており、cが1度も出てきてません。
暗号だけの場合は、それでも別に構いませんが復号のことも考えるとあまりよくありません。bはaとzのどちらに復号すればよいか、分からなくなります。例外ですが、zは変換後cになるようにします。
aをASCIIコードで表すと97です。なので、96を引いて1 2 3…というように小さい数値で考えます。この時に、3で割りあまりの数で何文字ずらすか判断します。あまりが0の場合は99、1の場合は97、2の場合は98を足せばよいと分かります。しかし、xはaに変換に限っては大きな値から小さい値に変換する必要があり、普通に足すだけではできません。xは3で割り切れるので、あまりが0の場合は除法の計算を用いて考えます。3で割りきれる場合、97を引いて3を足します。その後、26で割りあまりを見ます。そのあまりと97を足すと3ずらすことができます。
3をずらしたい数に変更すれば、その分ずらすことできます。また、26で割る理由はアルファベットが26個のためです。数字に適応させる時など、必要に応じてこの値を変える必要があります。
cとxの2つ場合を考えてみましょう。ASCIIコードでcは99、xは120です。
cの場合
99-97=2 (2+3)/26=0…5 97+5=102
xの場合
120-97=23 (23+3)/26=1…0 97+0=97
上の計算式よりcがf、xがaになったことが分かります。
プログラムで表すと以下のようになります。
keyword.chars.each do |char| num1 = char.ord - 96 if (num1 == 26) then num3 = 99 elsif (num1 % 3 == 0) then num1 = num1 - 1 num2 = (num1 + 3) % 26 num3 = num2 + 97 elsif (num1 % 3 == 1) then num3 = num1 + 97 else num3 = num1 + 98 end code << num3.chr end
実行結果
パスワードを入力してください abcdefghijklmnopqrstuvwxyz 暗号化前: abcdefghijklmnopqrstuvwxyz 暗号化後: bdfegihjlkmonprqsutvxwyazc
私は、先ほど考えた反転の方程式と組み合わせてより複雑にしました。
そのプログラムを載せておきます。
keyword.chars.each do |char| if (97 <= char.ord && char.ord <= 122) then num1 = char.ord num2 = 109 - num1 num3 = 2 * num2 + 1 + num1 num4 = num3 - 96 if (num4 == 26) then num5 = 99 elsif (num4 % 3 == 0) then num4 = num4 - 1 num6 = (num4 + 3) % 26 num5 = num6 + 97 elsif (num4 % 3 == 1) then num5 = num4 + 97 else num5 = num4 + 98 end end code << num5.chr end
実行結果
パスワードを入力してください abc 暗号化前: abc 暗号化後: cza
3つ目は、入力した順に文字を1つ2つ3つずらす操作を繰り返す方程式です。
例えば、 0000 と入力すると 1231 というように変換されます。
3つ目の方程式はjという変数を用いて考えます。入力した数をjだけずらします。初めは、jに1を代入し入力されるたびにjの値を増加させます。jが3以上になれば再びjに1を代入します。
プログラムで表すと以下のようになります。
keyword.chars.each do |char| if(48 <= char.ord && char.ord <= 58)then num1 = char.ord - 48 num2 = (num1 + j) % 10 num3 = num2 + 48 if(j >= 3)then j = 1 else j = j + 1 end end code << num3.chr end
実行結果
パスワードを入力してください 000000 暗号化前: 000000 暗号化後: 123123
復号方程式
復号の方法ですが、暗号の方法とあまり変わりません。
1つ目の復号方程式ですが、暗号方程式と同じです。要するに、もう一度反転作業を行えばよいだけです。
順番を少し変えて3つ目の復号方程式について説明します。これもほとんど暗号方程式と同じです。暗号化する際、jを足して文字をずらしました。なので、復号する際はjを引いて文字ずらします。
プログラムで表すと以下のようになります。
j=1 keyword.chars.each do |char| if(48 <= char.ord && char.ord <= 58)then num1 = char.ord - 48 num2 = (num1 - j) % 10 num3 = num2 + 48 if(j >= 3)then j = 1 else j = j + 1 end end code << num3.chr end
実行結果
パスワードを入力してください 123123 復号前: 123123 復号後: 000000
最後に2つ目の復号方程式は、どれだけ数を足せば3で割り切れるかでずらす値を判断します。
暗号化の際、文字を1つずらしたものは、3で割ってあまりが2になるものに変換されます。なので、1を足せば3で割り切れる値になります。よって、1を足して3で割り切れる値は1つ文字をずらして復号します。
文字を2つずらしたものは、3で割って余りが1になるものに変換されます。なので、2を足せば3で割り切れる値になります。よって、2を足して3で割りきれる値は2つずらして復号します。残った値は、3つずらし復号します。
暗号化の際、例外を1つ作りました。最初に例外の復号を行うことを忘れないようにしましょう。
プログラムで表すと以下のようになります。
keyword.chars.each do |char| if (97 <= char.ord && char.ord<=122)then num = char.ord if(num == 97)then num3 =120 elsif((num+1)%3==0)then num1 = num - 97 num2 = (num1 - 1) % 26 num3 = num2 + 97 elsif((num+2)%3==0)then num1 = num - 97 num2 = (num1 - 2) % 26 num3 = num2 + 97 else num1 = num - 97 num2 = (num1 - 3) % 26 num3 = num2 + 97 end end code << num3.chr end
実行結果
パスワードを入力してください bdfegihjlkmonprqsutvxwyazc 復号前: bdfegihjlkmonprqsutvxwyazc 復号後: abcdefghijklmnopqrstuvwxyz
私は、少し複雑な暗号にしたのでその復号のプログラムも載せておきます。
keyword.chars.each do |char| if (97 <= char.ord && char.ord<=122)then num = char.ord if(num == 97)then num3 =120 elsif((num+1)%3==0)then num1 = num - 97 num2 = (num1 - 1) % 26 num3 = num2 + 97 elsif((num+2)%3==0)then num1 = num - 97 num2 = (num1 - 2) % 26 num3 = num2 + 97 else num1 = num - 97 num2 = (num1 - 3) % 26 num3 = num2 + 97 end num4 = 109 - num3 num5 = 2 * num4 + 1 + num3 end code << num5.chr end
実行結果
パスワードを入力してください cza 復号前: cza 復号後: abc
追記
内容が思っていたよりも多くなったので、その2に続きます。